
Zero-code BPM is not a Myth
A debate has been raging in the BPM community regarding Zero-Code BPM. The question is whether business processes can be run without coding. The debate has been not about desirability (everyone agrees it is desirable) but rather about feasibility.

Zero-Code BPM
One of the proponents of the view that Zero Code BPM is possible is Keith Swenson. In his post Zero-Code BPM Systems he makes several points. One point is that code comes in many forms. In particular visual drag and drop is code because it requires code-like thinking. A second is that a no-code BPM system will not “look” like a BPM system. This is because BPM systems as currently conceptualized are about detailed control rather than about individuals self-organizing to perform work.
We are in complete agreement with this point of view.
In the epilog to their book Business Process Management, The Third Wave, Howard Smith and Peter Fingar state
Some may still want to prevent managers from defining business processes themselves, saying it is too complex a job and should be left to specialists. That may be true right now, but it won’t be by the week after next.
They cite the Spreadsheet as the paradigmatic example of empowering business users.
The spreadsheet is a simple yet eloquent example of a useful paradigm shift. The convenience and low cost of the breakthrough was so striking that it led to the PC revolution in business. The spreadsheet could not have been successful had it not been for the fact that personal computers–a standards-based commodity–were spreading like wild-fire elsewhere in society. To the business, the PC loaded with a spread-sheet meant a radical simplification of routine calculations, transferring to the everyday business person a function that had once required special programming skills. [emphasis added]
The contrarian view is articulated by Gavin O’Kane in his article Zero-Code BPM – Wishful Thinking. He makes two main points in this article. The first point is a definitional one, viz. that BPM is about control.
As soon as we talk about exercising control over anything, we have our own set of rules and regulations. Rules and regulations extends the power of decision making capacity. It ensures that all the tasks are performed within the pre-defined framework
But is BPM (solely) about control? In many instances it is about control. However, BPM in the context of knowledge workers is not mostly about control. It is mostly about guidance and goal management. Some have sought to use different language to describe knowledge-worker-oriented BPM. The term most used in this regard is Adaptive Case Management.
From our perspective, knowledge workers do require and do participate in self-organizing business processes. Our position is that BPM is made up of control-oriented processes and self-organizing, goal-oriented processes.
The second point that integration requires code is clearly true. We address this point later in this article.
So, in summary this article is making three points about a Knowledge-worker-oriented BPM system
- It will “look” different from a traditional BPM system.
- The knowledge worker, not the analyst or coder will (and should) be in the driver’s seat.
- It will not (and should not) require coding
So, what would a knowledge-worker-oriented BPM system “look” like?
First we need to establish some of the requirements of such a system. Obviously it would need to allow knowledge workers to self-organize their process work. But more importantly, knowledge work is changing at an extremely rapid rate. The presumption that knowledge workers know the end-state of their process up-front needs to be questioned.
Furthermore, does the typical knowledge worker even think in terms of formal ‘processes’?
In our opinion, one of the reasons why BPM has had a modest success rate (despite its incredible potential) with knowledge work is its assumption that the end-state process can be known and that knowledge workers are even thinking about formal ‘processes’.
Knowledge workers do run processes. But they use email, shared documents, task management systems, spreadsheets, wikis etc. They may not even “know” they are running a ‘process’.
Based on this viewpoint, our view is that a BPM system geared towards knowledge work must allow ‘processes’ to emerge naturally from things that knowledge workers normally do. We’ve settled on Discussions as the base activity to get started with. A discussion is a natural activity knowledge workers engage in. A large percentage of knowledge-worker time is spent in email and chat. It is no coincidence that both these types of systems are discussion-oriented.
- From there it is a small step towards Goal-Oriented Discussions.
- And from there it is another small step towards goal-oriented discussions that incorporate further guidance and milestone and task management.
- And from there it is yet another small step towards recognizing recurring patterns and formalizing them as process templates.
We call these emergent processes, Lean Processes.

Lean Processes: Processes naturally emerge from simple discussions and goal-oriented discussions
A key underlying theme of Lean Processes is one of proceeding from the informal to the formal. In this regard this approach is very similar to how spreadsheets are used. Very few users start with the ultimate end-state spreadsheet that solves everything. Instead they start with examples, recognize patterns, get feedback, improve their understanding and keep iterating and improving. Eventually the spreadsheet may get institutionalized into a reusable template.
This movement from the informal to the formal has some key benefits.
Firstly, the knowledge worker does not have the cognitive overhead of thinking about processes up front. They just discuss things. There is no pressure to move down the formalization spectrum. They only move down the formalization spectrum if it is warranted by the situation.
Secondly, this iteration and experimentation leads to what we call the Minimum Viable Process (similar to the Minimum Viable Product from the Lean Startup methodology). This way processes can be rapidly used in the real world, be modified with real-world feedback before expensive formalization is done. This is the heart of the Lean Methodology.
Now back to the original topic regarding “no-code”. The one obvious area that code may be required is integration.
Our approach on the matter of integration code is an approach we call Code-Later. What this means is that the system needs to be designed in such a way that user iteration and experimentation does not require any coding. Once a process has been stabilized and optionally formalized, only then should coding for integration purposes be introduced if needed. To the extent any coding is required it must not interfere with the knowledge worker’s ability to run processes.
What would a Code-Later approach look like? Obviously API’s play a part. But they are not the whole story. In the Lean Process approach, all states of a process are retained and automatically labeled (in a full audit trail). In the early stages of process evolution the process states are human-meaningful, but not necessarily machine-meaningful. As the process is solidified it can later (optionally) be made machine-meaningful. Knowledge workers can lay down (named) markers on certain machine-meaningful states which in turn trigger (coded) integrations.
This article on Process-Centric Collaboration describes how Lean Processes are moved from one meaningful state to another.
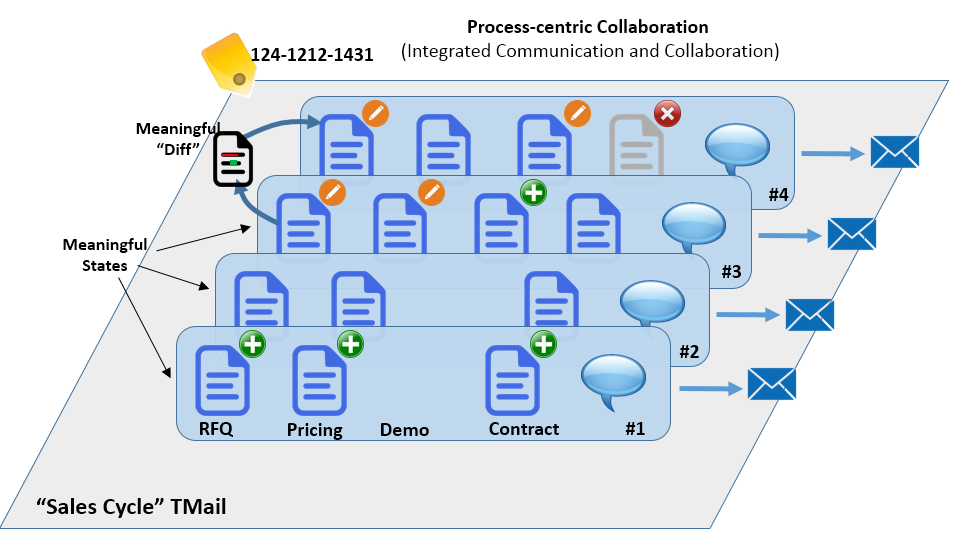
So, does the Code-Later integration approach mean that No-code-bpm is a myth? We would argue ‘no’ based on
- It is entirely optional. Many, if not most, lean processes will not require integration.
- The coding occurs late in the hardening cycle and does not interfere with the rapid iteration so necessary for successfully implementing knowledge worker processes.
- (Integration) codification even when it does occur, does not interfere with the knowledge worker’s ability to execute the process. The knowledge worker merely needs to evolve the process towards a machine-meaningful state. This machine-meaningful-state combined with named markers is essentially an API against which integration software developers can write adapters.
In summary, a new kind of BPM system can empower knowledge workers to execute processes while not requiring them to engage in coding. This approach has the potential to make knowledge workers (and hence businesses) more productive and agile.
You can get started with Zero-code BPM and Lean Processes for free by registering for TMail21.

